
Implementacja Microsoft Fabric
Ten artykuł poprowadzi Cię przez najważniejsze aspekty wdrożenia Microsoft Fabric:
1. Wprowadzenie do Microsoft Fabric
2. Kto powinien wdrożyć Microsoft Fabric?
3. Kluczowe korzyści z Microsoft Fabric
4. Wyjaśnienie komponentów Microsoft Fabric
5. Zrozumienie architektury Medallion w Microsoft Fabric
6. Licencjonowanie, ceny i koszty Microsoft Fabric
7. Najlepsze praktyki dla udanego wdrożenia Microsoft Fabric
1. Wprowadzenie do Microsoft Fabric
Microsoft Fabric to kompleksowa platforma danych oparta na sztucznej inteligencji, zaprojektowana w celu ujednolicenia przechowywania danych, zarządzania nimi, analizy i analizy biznesowej (BI) z różnych źródeł. Jako część pakietu chmurowych rozwiązań Microsoft do obsługi danych, pomaga organizacjom usprawnić integrację danych, zwiększyć możliwości analityczne i usprawnić podejmowanie decyzji.
Dlaczego Microsoft Fabric?

2. Kto powinien wdrożyć Microsoft Fabric?
Dzięki zintegrowanej architekturze Microsoft Fabric umożliwia firmom uwolnienie pełnego potencjału ich danych – czy to do analizy w czasie rzeczywistym, wniosków opartych na sztucznej inteligencji, czy raportowania korporacyjnego.
3. Kluczowe korzyści z Microsoft Fabric
Microsoft Fabric oferuje ujednoliconą, opartą na współpracy i skalowalną platformę danych, która upraszcza zarządzanie danymi, analitykę i optymalizację kosztów. Zamiast polegać na wielu, niepołączonych usługach analitycznych, organizacje mogą wykorzystać usprawnione, kompleksowe rozwiązanie, które jest łatwe do wdrożenia, integracji i obsługi.
Największe korzyści z Microsoft Fabric:
Wdrażając Microsoft Fabric, firmy zyskują scentralizowane, oparte na sztucznej inteligencji i opłacalne rozwiązanie do obsługi danych, które usprawnia współpracę, bezpieczeństwo i możliwości analityczne – a wszystko tow zarządzanym, skalowalnym i wysokowydajnym środowisku.
4. Wyjaśnienie komponentów Microsoft Fabric
Data Factory – Usprawniona integracja danych
Oparta na chmurze oferta usług integracji danych:
Co-Pilot – Pomoc i automatyzacja oparta na sztucznej inteligencji
Kontekstowy zestaw narzędzi AI, który zwiększa produktywność poprzez:
OneLake – Ujednolicone przechowywanie danych w chmurze
Scentralizowane jezioro danych oparte na usłudze Azure Data Lake Storage Gen2:
Power BI – Interaktywna wizualizacja i analiza danych
Wiodące narzędzie BI w ramach Microsoft Fabric, umożliwiające:
Inżynieria danych – transformacja danych na dużą skalę
Potężny obszar roboczy, który pozwala:
Data Science – AI & Machine Learning Capabilities
W pełni zintegrowany system ML envoirement, oferujący:
Hurtownia danych – wysokowydajna pamięć analityczna
W pełni zarządzana, skalowalna hurtownia danych:
Inteligencja w czasie rzeczywistym – szybka analiza strumieniowa
Rozwiązanie do przetwarzania danych w czasie rzeczywistym, umożliwiające:
Microsoft Pureview – Zarządzanie danymi i zgodność z przepisami
Solidne rozwiązanie do zarządzania danymi i zapewniania zgodności z przepisami:
Dodatkowe funkcje Microsoft Fabric
Apache Spark – Skalowalny silnik przetwarzania danych
Wysokowydajny framework dla:
Data Pipelines – Zautomatyzowane zarządzanie przepływem danych
Skalowalna platforma integracji danych, umożliwiająca:
Data Lakehouse – Hybrydowe rozwiązanie do przechowywania i analizy danych
Potężne rozwiązanie hybrydowe łączące Data Lakes i Hurtownie Danych:
Aby dowiedzieć się więcej o praktycznym zastosowaniu tych narzędzi, obejrzyj poniższy webinar, z omówieniem praktycznego case-study!
5. Zrozumienie architektury Medallion w Microsoft Fabric
Architektura Medallion to ustrukturyzowany wzorzec projektowania danych, który poprawia jakość, strukturę i użyteczność danych, gdy przechodzą one przez wiele warstw przetwarzania przyrostowego. Takie podejście zapewnia, że dane są zgodne z właściwościami ACID (Atomicity, Consistency, Isolation, Durability), zanim dotrą do ostatecznej warstwy przechowywania i analizy, dzięki czemu są niezawodne, skalowalne i zoptymalizowane pod kątem analizy.
Architektura ta jest podzielona na trzy logiczne warstwy oparte na jakości i udoskonalaniu danych:
1. Warstwa Brązowa – surowe dane
2. Warstwa Srebrna – oczyszczone, znormalizowane dane
3. Warstwa Złota – zoptymalizowane i wzbogacone dane do analizy
Postępując zgodnie z tym ustrukturyzowanym modelem Lakehouse, firmy mogą zmaksymalizować użyteczność danych, poprawić zarządzanie i usprawnić przepływy pracy analitycznej w ramach Microsoft Fabric.
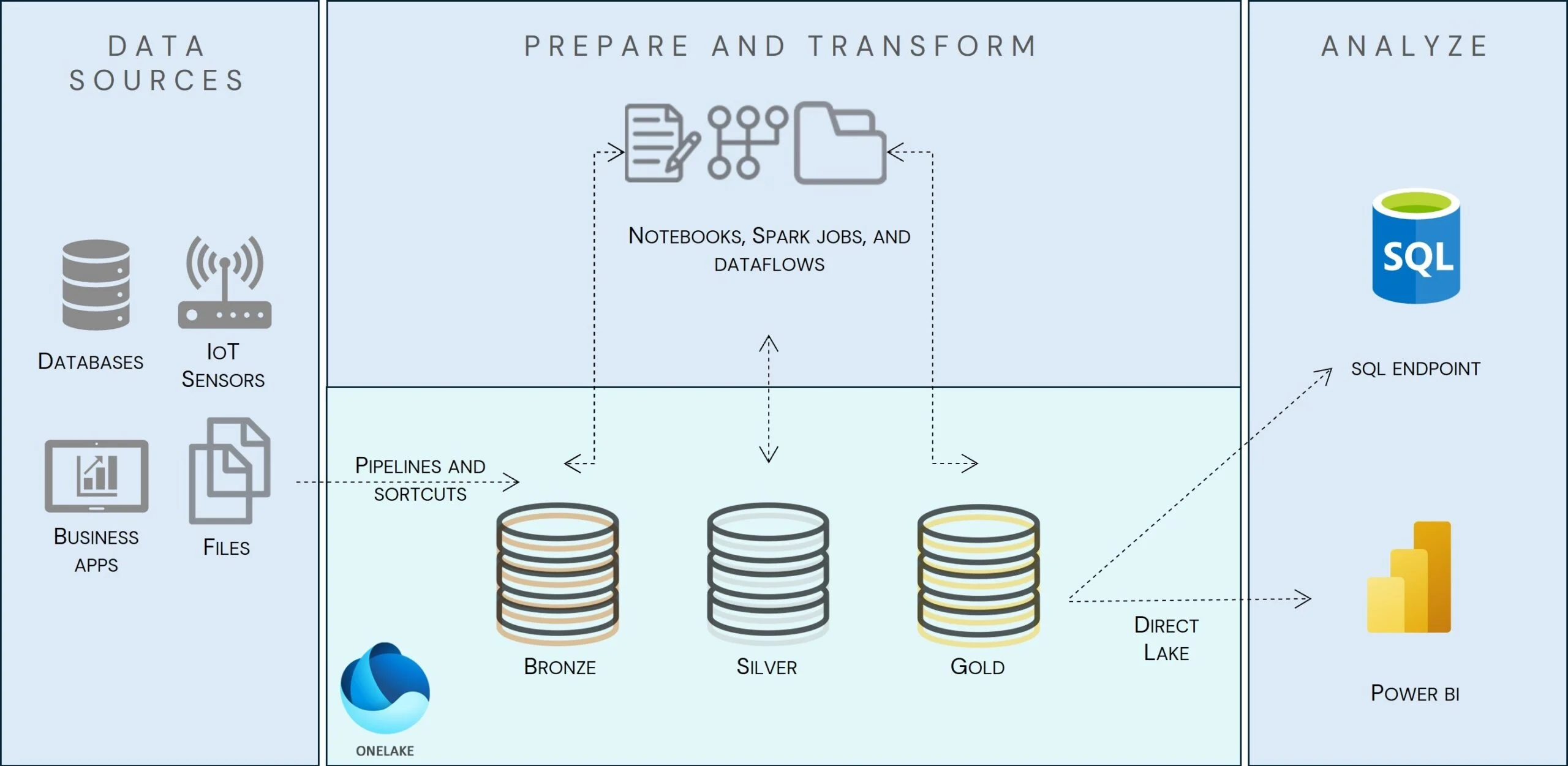
Opis warstw
1. Warstwa brązowa – pozyskiwanie i przechowywanie surowych danych
Cel:
Miejsce zapisu surowych, nieprzetworzonych danych
Źródła danych:
Data Factory, Data Pipelines i skróty są używane do pozyskiwania danych
Źródła obejmują bazy danych, interfejsy API, urządzenia IoT, pliki zewnętrzne i platformy innych firm
Kluczowe cechy:
Przypadek użycia:
Przechowywanie nieprzetworzonych dzienników z urządzenia IoT przed przetworzeniem
2. Srebrna warstwa – oczyszczone i znormalizowane dane
Cel:
Poprawia jakość, spójność i integrację danych
Narzędzia przetwarzania:
Spark Jobs, Spark Notebooks i Fabric Dataflows do transformacji
Kluczowe cechy:
Przypadek użycia:
Czyszczenie danych transakcji sprzedaży z różnych sklepów i łączenie ich w ustrukturyzowany zbiór danych
3. Złota warstwa – zoptymalizowane dane gotowe do wykorzystania w biznesie
Cel:
Zapewnia wyrafinowane, ustrukturyzowane i zagregowane dane do analizy
Narzędzia do przetwarzania:
Obciążenia inżynierii danych do agregacji, indeksowania i optymalizacji
Kluczowe cechy:
Przypadek użycia:
Generowanie analizy trendów przychodów poprzez agregowanie danych sprzedaży według regionu
6. Licencjonowanie, ceny i koszty Microsoft Fabric
Microsoft Fabric oferuje elastyczne plany cenowe zaprojektowane z myślą o firmach różnej wielkości, od startupów po duże przedsiębiorstwa. Model płatności zgodnie z rzeczywistym użyciem zapewnia, że organizacje płacą tylko za zasoby, z których korzystają, dzięki czemu jest to opłacalne i skalowalne rozwiązanie do obsługi danych.
Model cenowy Microsoft Fabric
Microsoft Fabric działa zgodnie z modelem licencjonowania opartym na pojemności, co oznacza, że kupujesz pojemność obliczeniową, a nie poszczególne usługi. Ceny są oparte na:
Przykład: Jeśli organizacja wymaga intensywnego przetwarzania danych do analizy w czasie rzeczywistym, może być potrzebna wyższa warstwa CU do obsługi wydajności.
Czynniki wpływające na koszt Microsoft Fabric
Opcje licencjonowania Microsoft Fabric
Microsoft Fabric jest dostępny jako część Power BI Premium, co oznacza, że istniejący użytkownicy Power BI mogą korzystać z Fabric bez konieczności posiadania oddzielnej licencji.
Jak zoptymalizować koszty Microsoft Fabric?
Dlaczego Microsoft Fabric jest opłacalny?
Potrzebujesz pomocy w wyborze odpowiedniego planu Microsoft Fabric?
Skontaktuj się z nami, aby uzyskać poradę eksperta
Zarezerwuj konsultację telefoniczną, a my skontaktujemy się z Tobą.
7. Najlepsze praktyki dla udanego wdrożenia Microsoft Fabric
Wdrożenie Microsoft Fabric wymaga strategicznego podejścia, aby zapewnić płynne wdrożenie, bezproblemową integrację danych i optymalną wydajność. Dzięki zebraniu wielofunkcyjnego zespołu wdrożeniowego i przestrzeganiu najlepszych praktyk, organizacje mogą zmaksymalizować wartość swojej platformy danych, jednocześnie minimalizując ryzyko i nieefektywność.
1. Zebranie wielofunkcyjnego zespołu wdrożeniowego
Pomyślne wdrożenie Microsoft Fabric wymaga współpracy między działem IT, interesariuszami biznesowymi i doświadczonym partnerem.
Zespół IT: Odpowiedzialny za konfigurację techniczną, integrację, bezpieczeństwo i optymalizację wydajności.
Zespół biznesowy: Definiuje przypadki użycia, potrzeby raportowania i zasady zarządzania danymi, aby zapewnić zgodność z celami biznesowymi.
Delivery Partner (Antdata): Zapewnia specjalistyczną wiedzę w zakresie architektury, wdrażania i dostosowywania, zapewniając płynne i wydajne wdrożenie.
Dlaczego warto współpracować z partnerem Microsoft, takim jak Antdata?
2. Zdefiniowanie jasnych celów biznesowych i przypadków użycia
Przed wdrożeniem Microsoft Fabric należy zidentyfikować kluczowe cele biznesowe i sposób, w jaki platforma będzie je wspierać.
Przykład:
Cel: Poprawa analityki w czasie rzeczywistym w celu uzyskania wglądu w zachowania klientów
Przypadek użycia: Wykorzystanie funkcji Real-Time Intelligence w Microsoft Fabric do przetwarzania danych na żywo dotyczących wydajności linii produkcyjnych (OEE).
3. Opracowanie skalowalnej strategii danych
Microsoft Fabric został zaprojektowany z myślą o skalowalności, więc jest niezbędny:
4. Zapewnienie bezpieczeństwa, zgodności i zarządzania
Dzięki narzędziom bezpieczeństwa i zgodności klasy korporacyjnej organizacje powinny:
5. Optymalizacja kosztów dzięki inteligentnej alokacji zasobów
Aby kontrolować koszty i zmaksymalizować wydajność, należy rozważyć:
6. Włącz samoobsługową analitykę i analizy oparte na sztucznej inteligencji
Wzmocnienie pozycji zespołów w całej organizacji:
7. Współpraca z ekspertami w celu sprawnego wdrożenia
Współpraca z certyfikowanym partnerem Microsoft, takim jak Antdata, zapewnia:
Skontaktuj się z nami
Zarezerwuj termin telefonicznej konsultacji.
Wybierz datę telefonicznej konsultacji.
